Once every two and a half minutes, around the clock, for 174 consecutive days, an AI company requested a page from one of our servers. Not a person asking a chatbot a question — though that happens too, and we counted it separately — but a machine with a name like GPTBot or Bytespider or ClaudeBot, identifying itself in its user-agent string and working through our sites the way Googlebot has worked through the web for twenty-five years.
The conventional wisdom about web crawling was settled a long time ago: Googlebot is the biggest visitor you will never see, a handful of other search engines trail far behind it, and the whole arrangement is governed by an informal deal — you let the crawler in, the search engine sends you readers. Every robots.txt file on the Internet was written inside that bargain. The AI crawl breaks the bargain's economics: a training crawler takes the content and, by design, never sends anyone back. Publishers have responded with blanket blocks, licensing deals, and lawsuits, but most of the discourse runs on anecdote — a Cloudflare aggregate here, an angry server bill there. Very few operators publish their raw crawler ledger.
We can. Since January 2026, LLMSE and this site have logged and classified the user-agent of every HTTP request they receive into a shared measurement store — browsers, libraries, classic crawlers, and a category we built specifically for this moment: AI crawlers, matched against the published user-agent tokens of every major AI operator. One of the two properties also runs a honeypot: a URL disallowed for every agent in robots.txt, invisible to humans, that permanently blocks any IP that touches it. The census below covers 1,348,706 requests carrying 14,970 distinct user-agent strings, observed 11 January through 3 July 2026, with every AI-crawler request attributed to a named bot, a named operator, and a declared purpose.
The headline: AI crawlers generated 97,454 requests — more than every classic search engine crawler combined (92,827), and 1.4 times Googlebot alone. Two years after GPTBot's user-agent first appeared in server logs anywhere, the AI industry collectively out-knocks the search industry on our infrastructure. What follows is who those crawlers are, what they came for, and — courtesy of the honeypot — which of them actually read the rules before walking in.
The Data
| Traffic category | Unique UA strings | Requests | Share of all requests |
|---|---|---|---|
| HTTP libraries (curl, python-requests, Go…) | 84 | 445,259 | 33.0% |
| Classic crawlers & bots | 400 | 435,983 | 32.3% |
| Browsers (desktop) | 4,776 | 295,617 | 21.9% |
| AI crawlers | 80 | 97,454 | 7.2% |
| Browsers (mobile) | 2,907 | 39,215 | 2.9% |
| Unknown | 6,541 | 33,217 | 2.5% |
| Browsers (tablet) | 148 | 975 | 0.1% |
| Social media preview bots | 18 | 918 | 0.1% |
| Other (email, media, feed) | 11 | 63 | <0.1% |
| Total | 14,970 | 1,348,706 | 100% |
Download: ai-crawler-census-traffic-mix.csv. Category rows sum to 1,348,701 requests across 14,965 strings: five user-agent records (5 requests total) were counted by the global counters but retired from the category indexes during the window, and are excluded from per-category rows.
Every request is counted once, attributed to its full user-agent string, and classified by a rule engine described below. The first thing the table says has nothing to do with AI: at most 25% of the traffic to these two properties comes from anything resembling a human browser. HTTP libraries and declared crawlers together account for 65%, and a fair share of the "Unknown" and "browser" categories is automation wearing a costume — a point the honeypot data will make concrete. The AI crawl, at 7.2% of everything, is no longer a curiosity line item; it is a top-four traffic category on its own.
Methodology
Dataset scope. Two production web properties — llmse.ai (an LLM-powered search engine and website analytics service) and domainsproject.org (this site) — record the User-Agent header of every HTTP request into a shared Redis measurement store. Each distinct UA string is hashed and stored once, with a cumulative hit counter and first-seen/last-seen timestamps. The observation window opens 11 January 2026 (when tracking went live) and closes 3 July 2026, 174 days later. Requests are counted at the application layer, after CDN/proxy handling; static-asset requests served upstream are not included.
Classification. Every UA string is parsed and assigned exactly one category:
- AI crawler — the string contains one of 19 published AI-operator tokens: GPTBot, OAI-SearchBot, ChatGPT-User (OpenAI); ClaudeBot, Claude-User (Anthropic); Google-Extended; PerplexityBot, Perplexity-User; Meta-ExternalAgent; Bytespider (ByteDance); CCBot (Common Crawl); Amazonbot; cohere-ai; YouBot; Diffbot; Omgilibot; ImageSiftBot; AI2Bot; Applebot-Extended. AI matching runs before generic bot detection, so an AI crawler is never double-counted as a classic crawler.
- Classic crawler/bot — identified as a bot by the parser (Googlebot, Bingbot, AhrefsBot, SemrushBot, monitoring agents…) without an AI token.
- Purpose — each AI bot is assigned one declared purpose from its operator's own documentation: training-data collection (GPTBot, ClaudeBot, Bytespider, Meta-ExternalAgent, CCBot, cohere-ai, Google-Extended…), AI search indexing (OAI-SearchBot, PerplexityBot, YouBot, Amazonbot), or user-triggered fetching — a fetch performed live because a human asked an assistant something (ChatGPT-User, Claude-User, Perplexity-User). Amazonbot is the borderline case: Amazon documents it as feeding Alexa's question-answering, so we file it under search indexing rather than training; readers who disagree can move its 16,779 requests between buckets in the per-bot CSV.
- Search engines, for the comparison set, are Googlebot, Bingbot, PetalBot, DuckDuckBot, and Baiduspider — crawlers whose operators run consumer search engines that send referral traffic. SEO-tool crawlers (AhrefsBot, SemrushBot, MJ12bot…) are tallied separately.
The honeypot. llmse.ai's robots.txt disallows the path /hp for User-agent: * — every agent, no exceptions. The path is linked in a way only automated link-followers encounter, never navigated to by humans. Any IP that requests it is logged (with its UA) and permanently blocked. Honeypot entries therefore count distinct trapped IPs, not requests — a different unit from the census tables.
Known limitations. These numbers are honest but not innocent, and five caveats matter. (1) User-agent strings are self-declared and unverified — we did not validate source IPs against operators' published ranges, so a scraper impersonating GPTBot inflates GPTBot, and conversely the 345 browser-masquerading honeypot catches show real crawl volume hides in the browser categories. Published-token counts are best read as attributed volume. (2) This is a two-property panel, both properties AI- and infrastructure-themed, which plausibly attracts heavier AI crawl than a florist's site; shares within categories travel better than absolute levels. (3) Counts merge both properties — the store increments one counter per UA string regardless of which site the request hit, so we cannot split per-site volumes. (4) First-seen dates are left-censored at 11 January 2026: seven of the 14 bots were already crawling on day one, so their true arrival predates the window. (5) Bytespider's count is a floor: from 7 February the honeypot began permanently blocking its IPs (124 of them), and blocked requests are rejected before they reach the user-agent tracker — its true demand was higher than its 17,169 recorded requests. Additionally, llmse.ai's robots.txt disallows one expensive path for eight named AI bots, which suppresses compliant bots' volumes relative to their intent — another reason compliant crawlers' totals are conservative.
Dataset vs external counts. Where our shares diverge from Cloudflare Radar's AI Insights — the closest thing to a global panel — we flag it inline. Directionally the two panels agree; the divergences are what a two-site panel with a robots.txt policy and a honeypot should produce, and we explain each one where it appears.
Reproducibility. Every table and chart in this post has a downloadable CSV: per-bot, traffic mix, vs incumbents, purpose split, and honeypot. Replicating the census on your own infrastructure requires only logging the User-Agent header and matching the 19 tokens listed above.
The Scorecard
| Bot | Operator | Declared purpose | Requests | Share of AI crawl | UA variants | First seen* | Last seen |
|---|---|---|---|---|---|---|---|
| GPTBot | OpenAI | Training | 25,495 | 26.2% | 5 | 11 Jan | 3 Jul |
| Bytespider | ByteDance | Training | 17,169 | 17.6% | 4 | 11 Jan | 3 Jul |
| Amazonbot | Amazon | Search/assistant | 16,779 | 17.2% | 2 | 11 Jan | 3 Jul |
| ClaudeBot | Anthropic | Training | 15,074 | 15.5% | 4 | 11 Jan | 3 Jul |
| ChatGPT-User | OpenAI | User-triggered fetch | 9,135 | 9.4% | 3 | 11 Jan | 3 Jul |
| Meta-ExternalAgent | Meta | Training | 6,677 | 6.9% | 2 | 11 Jan | 3 Jul |
| CCBot | Common Crawl | Open corpus | 2,734 | 2.8% | 1 | 14 Jan | 30 Jun |
| OAI-SearchBot | OpenAI | Search index | 2,410 | 2.5% | 7 | 11 Jan | 3 Jul |
| PerplexityBot | Perplexity | Search index | 1,784 | 1.8% | 3 | 13 Jan | 1 Jul |
| Claude-User | Anthropic | User-triggered fetch | 108 | 0.1% | 42 | 6 Mar | 2 Jul |
| Perplexity-User | Perplexity | User-triggered fetch | 42 | <0.1% | 3 | 4 Apr | 3 Jul |
| YouBot | You.com | Search index | 40 | <0.1% | 2 | 1 Apr | 1 Jul |
| cohere-ai | Cohere | Training | 6 | <0.1% | 1 | 31 May | 17 Jun |
| Google-Extended | Training control | 1 | <0.1% | 1 | 17 Jun | 17 Jun |
* First seen is left-censored: the window opens 11 Jan 2026, and every bot showing that date was already active when tracking began.
Download: ai-crawler-census-bots.csv
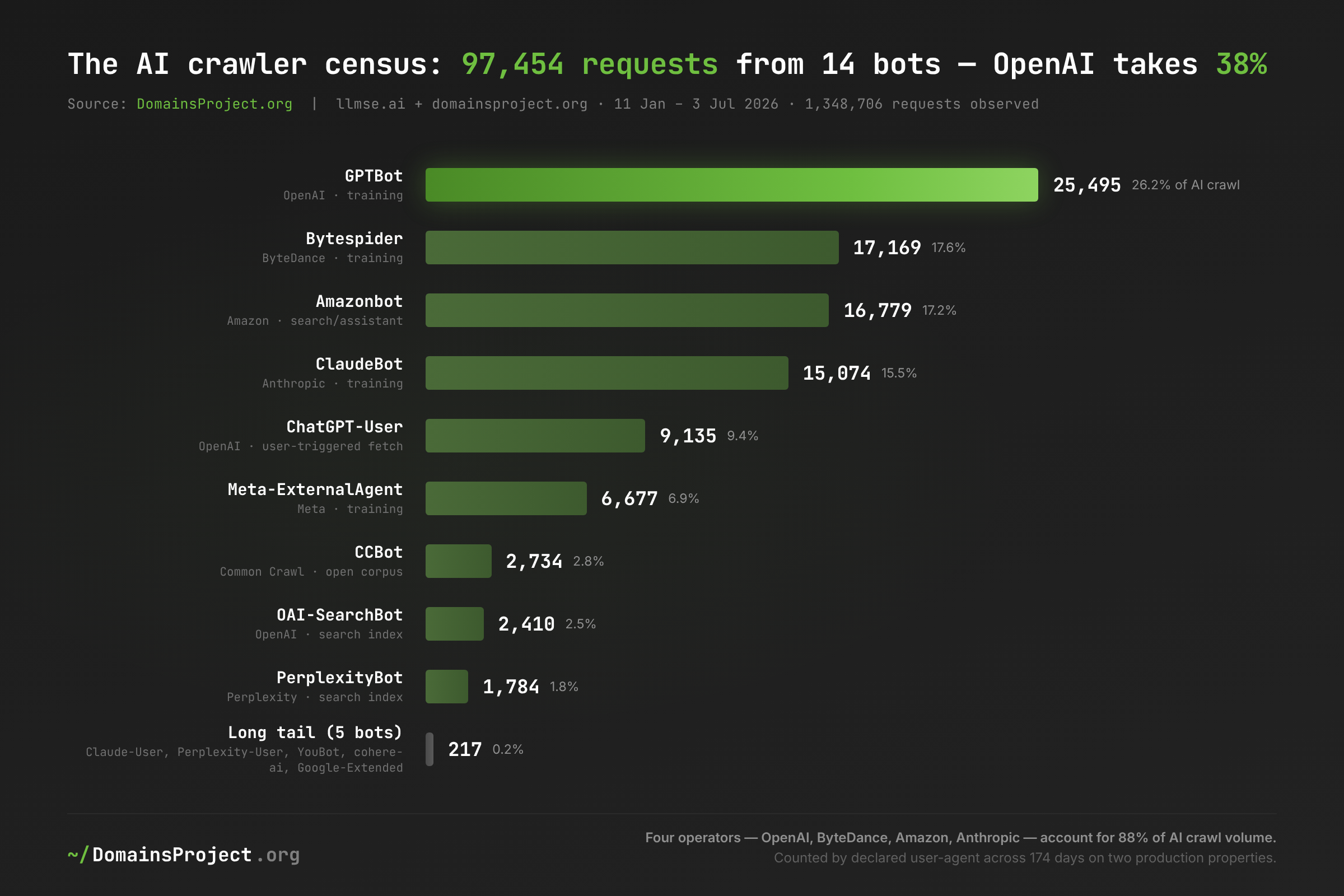
GPTBot is the busiest AI crawler on our panel. Its 25,495 requests — 147 a day, every day — exceed the next bot by nearly half, though the margin over Bytespider deserves an asterisk: we actively block Bytespider's IPs (see the honeypot section), so its count is a floor and the unblocked race would be closer. Global panels still put GPTBot ahead. Add ChatGPT-User and OAI-SearchBot and OpenAI alone accounts for 37,040 requests, 38% of the entire AI crawl — a single company generating more than half as much crawl load as Googlebot. The version trail in the UA strings shows an actively maintained fleet: GPTBot/1.3 carried 24,849 of those requests, with GPTBot/1.4 appearing mid-window.
The surprise in the top four is Amazonbot. The discourse about AI crawling is dominated by OpenAI and Anthropic, but Amazon's crawler — feeding Alexa's answers and Amazon's broader assistant ambitions — out-requested ClaudeBot on our panel. It arrives with none of the licensing-deal headlines and takes 17.2% of the crawl.
Operator concentration
| Operator | Requests | Share of AI crawl |
|---|---|---|
| OpenAI | 37,040 | 38.0% |
| ByteDance | 17,169 | 17.6% |
| Amazon | 16,779 | 17.2% |
| Anthropic | 15,182 | 15.6% |
| Meta | 6,677 | 6.9% |
| Common Crawl | 2,734 | 2.8% |
| Perplexity | 1,826 | 1.9% |
| You.com, Cohere, Google | 47 | <0.1% |
Four operators — OpenAI, ByteDance, Amazon, Anthropic — account for 88.4% of AI crawl volume. The AI crawl is already as concentrated as the industries it feeds: the same handful of labs that dominate model deployment dominate the demand side of the crawl economy. For a publisher deciding whose terms to negotiate, the long tail barely exists: everything below Meta rounds to noise.
Note the bottom row. Google-Extended appeared exactly once — because it is not really a crawler. It is a robots.txt control token: Google trains Gemini on what Googlebot already fetched for search, and Google-Extended exists only so publishers can opt out of that use. Google never sends it as a User-Agent header, so the one request carrying it was almost certainly a third-party tool or a spoof — we keep the row for completeness, but its real value is what it marks: the deepest structural asymmetry in the table. Every other AI operator had to send a new, blockable crawler onto the web; Google's training pipeline rides inside the crawler no publisher can afford to block. Our census, like any UA census, structurally undercounts Google's AI data collection for this reason.
The Old Guard: AI Crawlers vs Everyone Who Was Already Here
| Crawler | Type | Requests |
|---|---|---|
| All AI crawlers combined | AI | 97,454 |
| All search engines combined | Search | 92,827 |
| Googlebot | Search | 69,461 |
| AhrefsBot | SEO tooling | 39,019 |
| SemrushBot | SEO tooling | 27,005 |
| PetalBot | Search | 15,694 |
| DataForSeoBot | SEO tooling | 6,738 |
| Bingbot | Search | 6,717 |
| DotBot | SEO tooling | 5,219 |
| MJ12bot | SEO tooling | 4,089 |
| DuckDuckBot | Search | 506 |
| Baiduspider | Search | 449 |
Download: ai-crawler-census-vs-incumbents.csv. Same window, same properties, same counting method for every row.

The AI industry now sends more crawler traffic to our infrastructure than the entire search industry. 97,454 AI requests against 92,827 from every consumer search engine we could identify — Googlebot, Bingbot, Huawei's PetalBot, DuckDuckBot, and Baiduspider together. This is a same-panel, same-window, same-method comparison, so whatever biases our panel has apply to both sides of the ledger.
Three observations follow from the table. First, Googlebot is still the single busiest crawler on the web — 69,461 requests, 2.7× GPTBot — consistent with Cloudflare's finding that Googlebot remains the largest individual bot on their network. The AI crawl overtakes search only in aggregate. Second, Bingbot has quietly become a rounding error: 6,717 requests — a tenth of Googlebot, a quarter of SemrushBot — a remarkable data point given Bing's index feeds several AI search products. Third, the SEO-tooling economy (AhrefsBot + SemrushBot + MJ12bot + DotBot + DataForSeoBot, 82,070 requests combined) rivals the search engines themselves — the web has been carrying a second, invisible crawl economy for years, and the AI crawl has simply joined it as a third.
The proportions triangulate. On Cloudflare's global panel in May 2026, AI crawlers were 20.3% of verified bot traffic; on ours, AI crawlers are 18.3% of declared-crawler traffic (97,454 of 533,437). Two very different panels — one spanning millions of sites, one spanning two — land within two points of each other, which suggests the AI crawl share is a property of the 2026 web, not of our sample. Where we diverge is within the AI category: our GPTBot share of AI crawl (26.2%) is far above Cloudflare's (11.5% in May 2026), consistent with our panel being exactly the kind of technical, text-heavy content OpenAI crawls hardest, and with Bytespider — whose IPs we actively block — being suppressed on our panel while it surged on global ones.
Three Jobs, One Knock: Why They Crawl
| Purpose | Requests | Share of AI crawl | Bots |
|---|---|---|---|
| Training-data collection | 67,156 | 68.9% | GPTBot, Bytespider, ClaudeBot, Meta-ExternalAgent, CCBot, cohere-ai, Google-Extended |
| AI search indexing | 21,013 | 21.6% | Amazonbot, OAI-SearchBot, PerplexityBot, YouBot |
| User-triggered fetching | 9,285 | 9.5% | ChatGPT-User, Claude-User, Perplexity-User |
Download: ai-crawler-census-purpose.csv
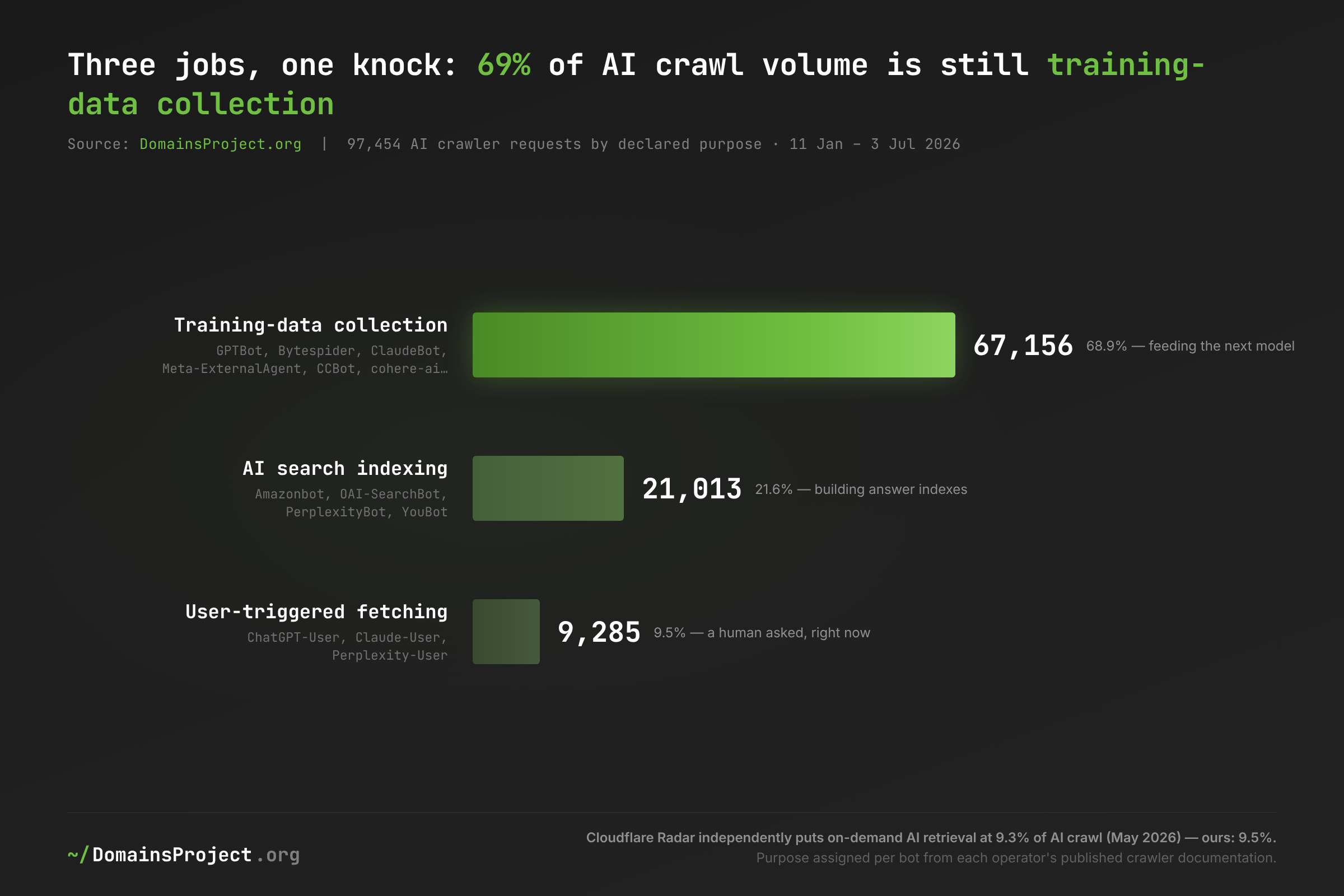
Sixty-nine percent of AI crawl volume still exists to feed the next model, not to answer the current question. The AI crawl is often defended by analogy to search — "we index, you get cited, readers come" — but the purpose split shows the analogy holds for less than a third of the traffic. Training crawls offer the publisher nothing back by design; the citation-and-referral story only applies to the 21.6% building answer indexes and the 9.5% fetching live.
That 9.5%, though, is the number to watch. User-triggered fetching — ChatGPT-User retrieving your page because a human just asked about it — is the closest thing the AI economy has to a pageview. Our share matches Cloudflare's independently measured 9.3% (May 2026) almost exactly, and external panels report the on-demand slice growing month over month while AI referral traffic grew 200%+ year over year. If those external trends hold, the base case is a slow rebalancing of the AI crawl away from bulk training ingestion toward per-question retrieval — the bull case for publishers being that retrieval implies attribution and referral; the bear case being that the answer engine cites you and the reader still never clicks. Our single-window census cannot distinguish these — it can only establish the 2026 baseline against which the next census will measure the drift.
The arrival dates sketch the industry's build-out in miniature. Everything already crawling on 11 January was infrastructure built in 2023-2025: the big training bots and ChatGPT-User. What arrived during the window is the second wave: Claude-User on 6 March, YouBot on 1 April, Perplexity-User on 4 April, cohere-ai on 31 May. And inside Claude-User hides the census's oddest population: 42 distinct UA variants producing just 108 requests — 40 of them versioned claude-code/2.1.x strings, from 2.1.87 through 2.1.195. The product names itself in the string: those are Claude Code coding agents fetching pages on behalf of individual developers, from a tool shipping new releases so fast that nearly every visit arrives wearing a different version number. Agentic fetching is still statistically tiny — but it is the only category where the user-agent churns weekly, which is what the leading edge of something looks like.
The Honeypot: Who Actually Reads robots.txt
| Agent | Trapped IPs | Category |
|---|---|---|
| Browser-masquerading scrapers | 345 | No bot identity |
| Bytespider | 124 | Declared AI crawler |
| ClaudeBot | 1 | Declared AI crawler |
| All 12 other AI crawlers | 0 | Declared AI crawler |
| Other declared bots | 1 | Classic crawler |
Download: ai-crawler-census-honeypot.csv. 471 IPs trapped 7 Feb – 29 Jun 2026 on a path disallowed for every agent; units are distinct IPs, not requests.
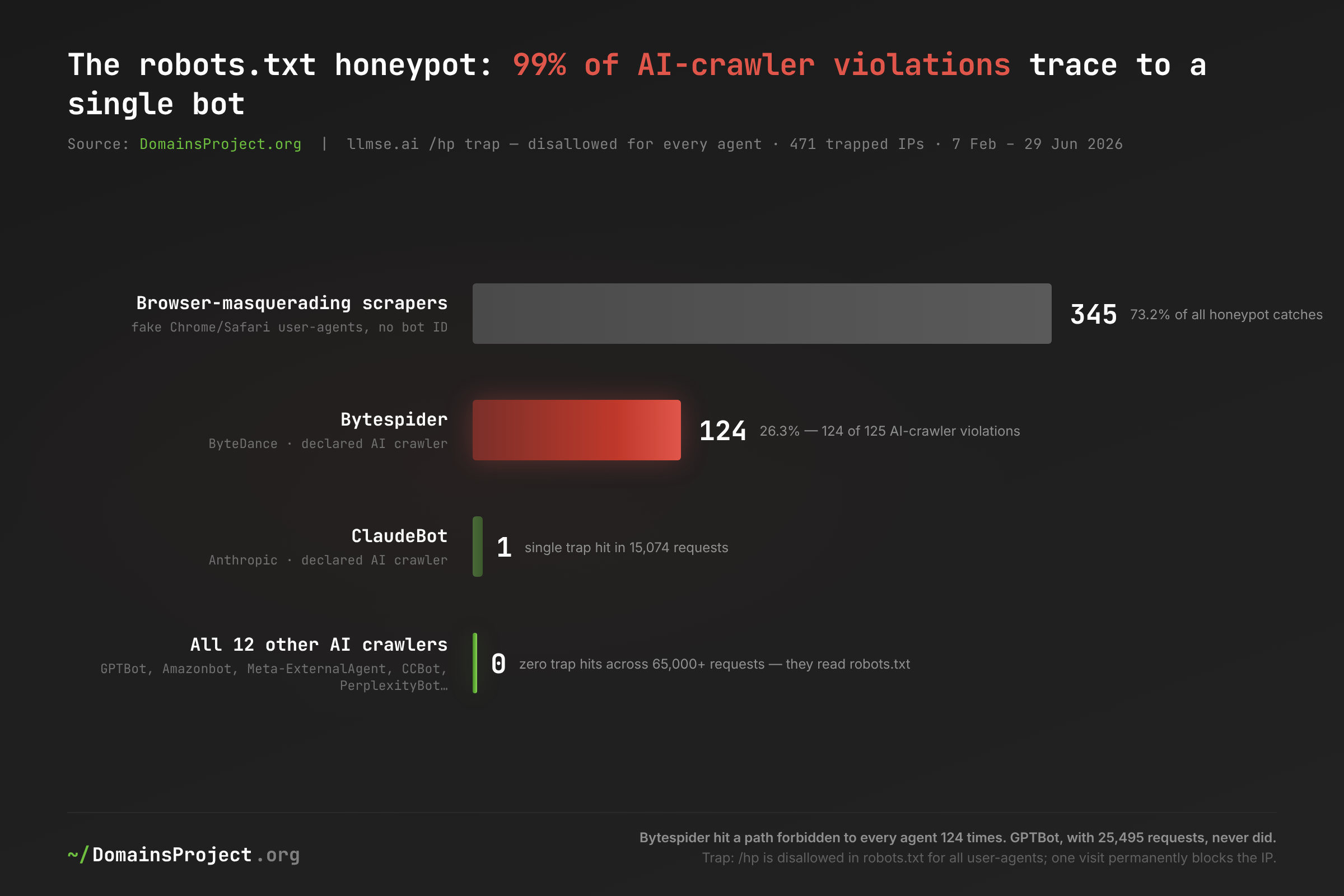
Of 125 honeypot violations by declared AI crawlers, 124 identified as Bytespider. The trap is a URL forbidden to every user-agent in robots.txt; touching it requires either not fetching the file or not caring what it says. GPTBot made 25,495 requests and never touched it. Amazonbot: 16,779 requests, zero. Meta-ExternalAgent, CCBot, PerplexityBot, OAI-SearchBot: zero, zero, zero, zero. ClaudeBot tripped it exactly once in 15,074 requests — a 0.007% rate consistent with a stale queue entry rather than a policy. Traffic calling itself Bytespider hit it from 124 different IP addresses.
Two caveats keep this honest. The trap is asymmetric: a hit is affirmative evidence of a violation, but zero hits is weaker evidence of compliance — a crawler working purely from a pre-computed URL list, never extracting links from pages, would miss the trap without ever consulting robots.txt. And UA strings are self-declared, so in principle those 124 IPs could be impostors wearing Bytespider's name — though the trap's own data cuts against that theory, since actual impostors overwhelmingly dress as browsers (345 of 471 catches), not as a blockable bot. What elevates the finding beyond one panel is corroboration: Bytespider's disregard for robots.txt is independently documented across multiple operator reports, with ByteDance officially claiming compliance while server logs across the industry say otherwise. On our panel, observed robots.txt violations among declared AI crawlers are close to binary: 99% of them arrive under ByteDance's flag, and none arrive under OpenAI's, Amazon's, or Meta's. Recall from the methodology that Bytespider's 17,169 census requests are a floor — every one of those 124 trapped IPs was permanently blocked at first touch, and its subsequent attempts were refused before they could be counted.
But the honeypot's larger lesson is the top row. 73% of everything the trap caught identified as an ordinary browser — fake Chrome and Safari strings with no bot identity at all. The named AI crawlers, whatever their table manners, are the visible part of the machine-reading economy; the trap suggests a substantial scraping population that never declares itself, some unknown share of which feeds AI pipelines through data brokers. A UA census like this one measures the crawlers polite enough to be counted — which means every AI-crawl number in this post, including the headline, is more plausibly an undercount than an overcount.
What's at Stake
- 7.2% of traffic, zero referrals by design — the training crawl (68.9% of AI volume) consumes bandwidth and compute and, unlike every search crawler in history, is architecturally incapable of sending a reader back. At our observed 560 AI requests/day across two mid-sized properties, the cost is real but manageable; scaled to media sites reporting multi-million daily AI crawler hits, it is an infrastructure line item with no revenue line against it.
- robots.txt works — for exactly the operators you worry about least. On our panel, every observed AI-crawler violation but one traced to a single operator; the labs with reputations and licensing deals at stake produced none. The instrument publishers are told to rely on filters the best-behaved traffic and passes the worst.
- Google's structural exemption is invisible in every census. Google-Extended is a paper token, not a crawler; Google's AI trains on Googlebot's index. Operators who block GPTBot and ClaudeBot but cannot afford to block Googlebot are, in effect, running an AI-training opt-out with a Google-shaped hole in it.
- Concentration cuts both ways. With 88.4% of the AI crawl in four hands, a publisher can cover most of the demand side with four negotiations — or four blocks. But it also means the terms of the machine-readable web are being set by four companies, none of which is obligated to keep sending the 9.5% of traffic that behaves like readership.
- The masked majority is the real measurement gap. If 73% of rule-breaking automation declares no identity, per-bot policy (blocking, licensing, rate-limiting by UA) governs a shrinking share of actual machine access. The policy conversation is about the crawlers we can name; the traffic is increasingly ones we cannot.
What Would Help
1. Publishers: measure your own ledger before setting policy. Blanket AI blocks are being deployed on vibes. The census above took a UA log and 19 string matches — an afternoon of work — and it changes the decision: blocking training bots touches 69% of AI volume at zero referral cost, while blocking user-fetchers (9.5%) severs the only AI traffic that resembles a reader. Replicate it: our CSVs and token list are the template.
2. AI operators: make identity verifiable, not just declared. Every number in this census rests on self-reported UA strings. Publishing signed request standards (Web Bot Auth-style) and stable IP ranges — as OpenAI and Anthropic already partially do — is what separates an accountable crawl economy from the masked 73%. An operator that wants its compliance record to count should make that record independently checkable.
3. ByteDance: the data says what it says. One operator accounts for 99% of identified AI-crawler robots.txt violations on our panel, corroborated industry-wide. Until Bytespider's behavior matches its documentation, every rational publisher's playbook will treat it as hostile traffic — server-level blocks rather than robots.txt requests — and its measured "compliance" will keep being an artifact of how many of its IPs are already banned.
4. Standards bodies: give purpose a protocol. The training/search/user-fetch distinction is the entire economics of the AI crawl, yet it lives in blog posts and inferred token names. A machine-readable purpose declaration — in the UA, in a request header, in robots.txt extensions like the emerging Content-Signals work — would let publishers permit retrieval while declining ingestion without maintaining a hand-curated bot list that goes stale monthly.
5. Researchers: multiply the panels. Ours is two properties; Cloudflare's is millions of sites but one vantage. The two agree on aggregate AI share (18-20% of bot traffic) and on the on-demand slice (9.3-9.5%), and disagree on per-bot mix — which is exactly the information multi-panel comparison surfaces. More operators publishing per-bot ledgers with consistent token lists would turn the AI-crawl debate from anecdote into measurement. The dataset and methodology here are open for exactly that.
This census classified the user-agent of 1,348,706 HTTP requests received by llmse.ai and domainsproject.org between 11 January and 3 July 2026 — 14,970 distinct user-agent strings, of which 80 matched the published tokens of 14 AI crawlers operated by 10 organizations. Honeypot data covers 471 IPs trapped on a universally disallowed path between 7 February and 29 June 2026. All user-agent identity is self-declared; per-bot figures are attributed, not IP-verified. External triangulation from Cloudflare Radar AI Insights and the industry reports linked inline. This post extends the AI-economy series begun with AI After the Gold Rush. Explore the domain statistics or work with the dataset yourself.